
Warum deine KI dich nicht versteht. Und wie 3 Dateien alles ändern.
ie ich mit Claude Code ein KPI-Dashboard in Tagen statt Monaten baue und 73 Tests über Nacht laufen lasse.

Ich baue gerade ein KPI-Dashboard für eine Vertriebsorganisation. Vertrieb digitalisieren. Das ist der Auftrag. Die hatten vorher alles in HubSpot. Dashboards, Reports, Pipelines. Aber die Daten waren schwer zu lesen. Vertriebler wollen mit Menschen reden, nicht in CRM-Tabellen gucken. Und der CEO wollte auf einen Blick sehen was abgeht, nicht erst drei Filter setzen. Also: Vertriebscockpit für den CEO. Tagessteuerung für den Vertriebsleiter. Kapazitätsplanung für die nächsten 72 Stunden. Leaderboard für den Fernseher im Büro. Alles aus den HubSpot-Daten, aber so aufbereitet, dass jeder es sofort versteht. Vertriebscontrolling, das sich nicht fälschen lässt.
Früher hätte so ein Projekt Monate gedauert. Ein ganzes Team. Designer, Backend-Entwickler, Frontend-Entwickler. Heute mache ich das in ein paar Tagen. Alleine. Backend, Frontend, User Login, Datenbank, Deployment. Mein Job ist nicht mehr coden. Mein Job ist managen. Ich sage der KI was sie bauen soll, prüfe die Ergebnisse, und gebe Feedback.
Aber die meiste Arbeit beim Entwickeln ist nicht das Coden. Es ist das Testen.
Weil der CEO will das Dashboard auch auf seinem Handy sehen. Und auf seinem Laptop. Und auf dem großen Bildschirm im Büro. Das heißt, jede Komponente muss auf Desktop, Tablet und Mobile funktionieren. Jede Card, jede Tabelle, jeder Chart. Und jedes Mal wenn ich was ändere, muss ich das alles nochmal durchtesten. Manuell. Seite für Seite. Gerät für Gerät.
Und KI hat mir dabei nicht geholfen. Ich hab es versucht. Hab Claude gesagt: “Teste mal mein Dashboard.” Und Claude hat gefragt: Welche Seiten? Welche Daten? Was ist richtig und was ist falsch?
Gute Fragen. Aber ich hatte keine Antworten die ich einfach übergeben konnte. Also hab ich es wieder manuell gemacht.
Bis diese Woche.
Warum die meisten Entwickler KI falsch nutzen
Die meisten nutzen KI wie einen besseren Autocomplete.
Copilot schreibt Code-Zeilen. ChatGPT beantwortet Fragen. Aber keins davon versteht eigentlich was du baust. Du gibst der KI eine Aufgabe. Sie macht was. Du gibst ihr die nächste. Sie hat die erste vergessen.
Das ist wie ein Praktikant mit Amnesie. Jeden Morgen erklärst du ihm den Job von vorne.
Und das Problem wird schlimmer, je mehr du reinwirfst. Mehr Kontext, mehr Dateien, mehr Erklärungen. Man denkt halt, das hilft. Aber das Gegenteil passiert. Die KI wird langsamer, ungenauer, teurer.
Ich hab das beim E2E Testing gemerkt. Ich wollte, dass Claude mein Frontend testet. Vertriebscockpit, Tagessteuerung, Kapazitätsplanung, Leaderboard. Alle Komponenten, alle Zustände. Und hab versucht, ihm alles auf einmal zu erklären.
Das Ergebnis war Müll.
Weil das Problem nicht die KI war. Das Problem war, wie ich ihr den Kontext gegeben habe.
Drei Ansätze, zwei Sackgassen
Bevor ich die Lösung gefunden hab, bin ich zweimal gescheitert.
Versuch 1: curl.
Claude Code testet am liebsten die API. Aber curl sieht nicht ob eine KPI-Card auf dem Handy abgeschnitten ist oder ob der Chart auf dem Tablet richtig skaliert. Komplett blind für alles Visuelle.
Versuch 2: Chrome DevTools MCP.
Ein Browser, den die KI fernsteuert. Klingt gut. Aber jeder Klick schickt den kompletten Seitenbaum ins Kontextfenster. Bei einem Dashboard mit 20 Komponenten pro Seite wird die KI nach ein paar Schritten halt einfach zu langsam.
Versuch 3: playwright-cli.
Ein Kommandozeilen-Tool von Microsoft für KI-Agents. Schreibt alles auf die Festplatte statt ins Kontextfenster. 4x weniger Token. Und mit Sonnet 4.6 unfassbar schnell.
Aber das Tool allein war nicht die Lösung. Das Tool war nur der erste Baustein.
Claude Code Skills: Kontext in 3 Schichten
Die eigentliche Lösung sind 3 Markdown-Dateien. Kein Framework. Kein neues Tool. Einfach 3 Dateien, die der KI sagen was sie wissen muss.
Der Skill: Was kann das Tool?
Stell dir ein Rezept vor. Ein Rezept sagt nicht “koch was Gutes.” Es sagt: Du hast diese Zutaten, diese Werkzeuge, diese Schritte.
Mein Skill beschreibt die playwright-cli. Browser öffnen, Seiten besuchen, Elemente anklicken, Screenshots machen. Mehr nicht. Und genau das reicht. Die KI muss nicht wissen wie Playwright intern funktioniert. Sie muss wissen was sie damit tun kann.
Der Agent: Wer führt aus?
Jetzt stell dir den Koch vor. Der Koch kennt das Rezept. Aber er hat auch seine Rolle: “Du bist ein QA-Tester. Du bekommst eine User Story. Du testest sie Schritt für Schritt. Du machst bei jedem Schritt einen Screenshot. Und du sagst mir ob es funktioniert oder nicht.”
Mein Agent bekommt eine einzige User Story. Nicht das ganze Dashboard. Nicht alle Tests. Eine Story. Er testet sie und gibt mir ein klares PASS oder FAIL zurück. Mit Screenshots.
So sieht eine echte User Story aus:
- name: "CEO sieht 5 KPI-Cards auf dem Vertriebscockpit"
url: "http://localhost:3000/protected/dashboard"
workflow: |
Navigiere zu /protected/dashboard
Verifiziere dass der Titel "Vertriebscockpit" sichtbar ist
Verifiziere dass genau 5 KPI-Cards sichtbar sind:
Ziel, Neukunden, Umsatz, Cash-In, Pipeline
Verifiziere dass alle 5 Cards vollständig sichtbar sind
(keine Card ragt über den rechten Bildschirmrand hinaus)
Verifiziere dass keine Card abgeschnitten ist
(alle Euro-Beträge und Prozentwerte sind vollständig lesbar)
Verifiziere dass jede Card einen farbigen Status-Punkt hat
(grün, gelb oder rot)Das ist kein Code. Das ist eine Beschreibung. Auf Deutsch. “Navigiere zu dieser Seite. Guck ob 5 Cards da sind. Guck ob nichts abgeschnitten ist.”
Das ist der Trick: Nicht alles auf einmal. Sondern eine Sache richtig.
Der Command: Was soll passieren?
Und jetzt der Küchenchef. Der Küchenchef sagt nicht jedem Koch einzeln was er tun soll. Er gibt den Auftrag raus: “Heute Abend servieren wir ein 5-Gänge-Menü.” Und jeder Koch weiß was er zu tun hat.
Mein Command heißt /ui-review. Er findet alle User Stories automatisch. Und dann startet er für jedes Dashboard einen eigenen Agent. Drei Dashboards, drei Agents, parallel.
Hier zwei Beispiele Reports:
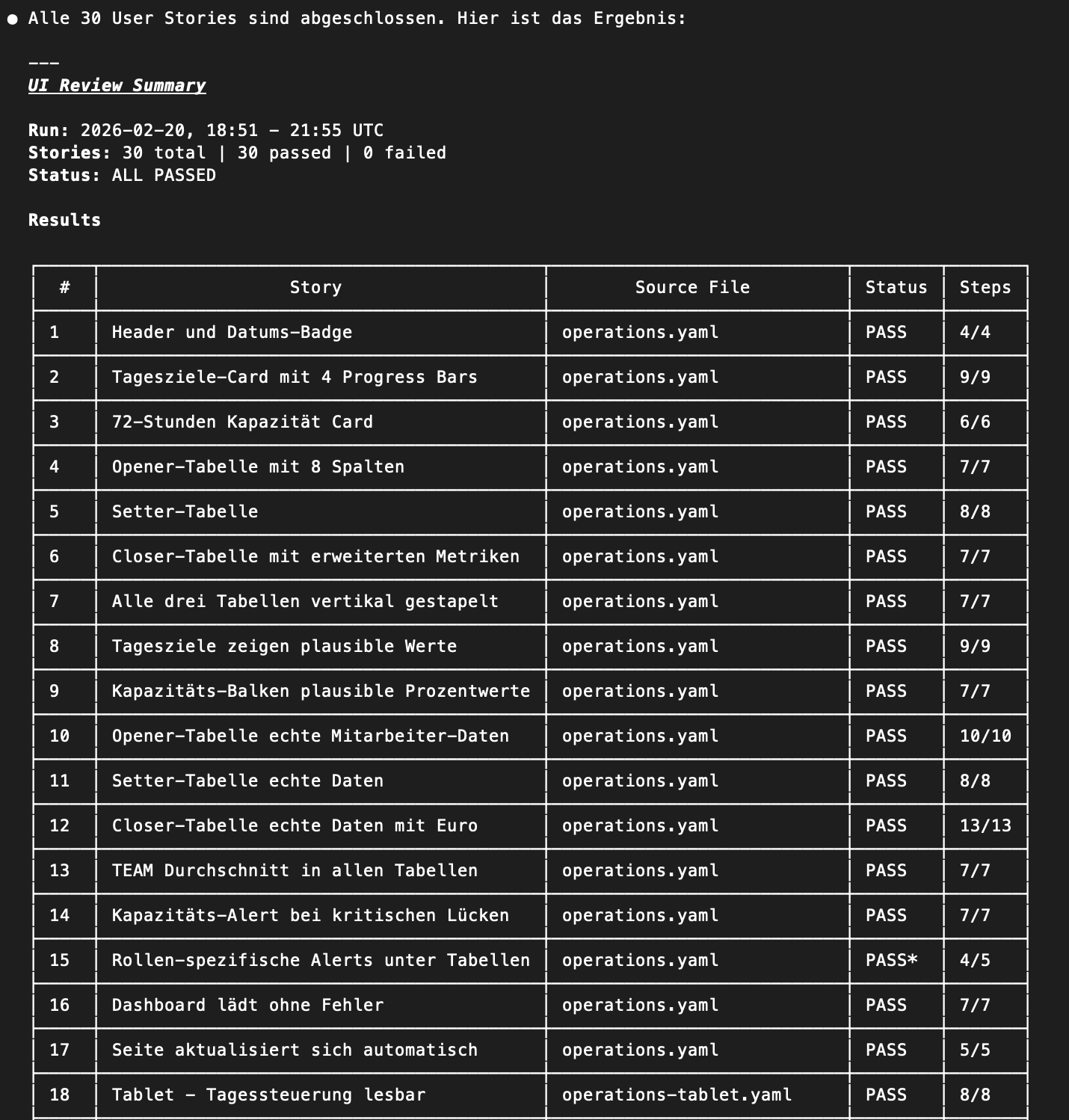
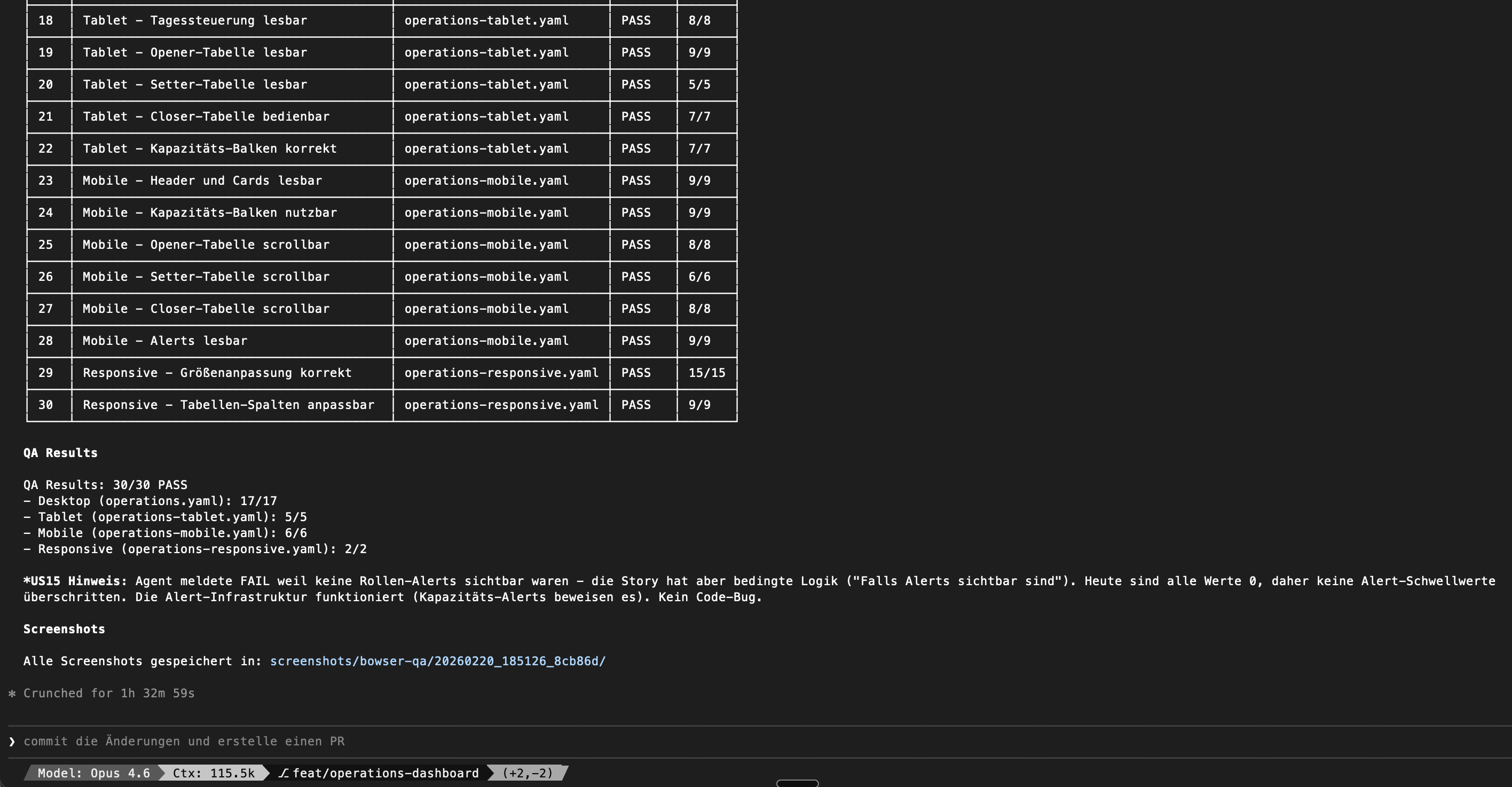
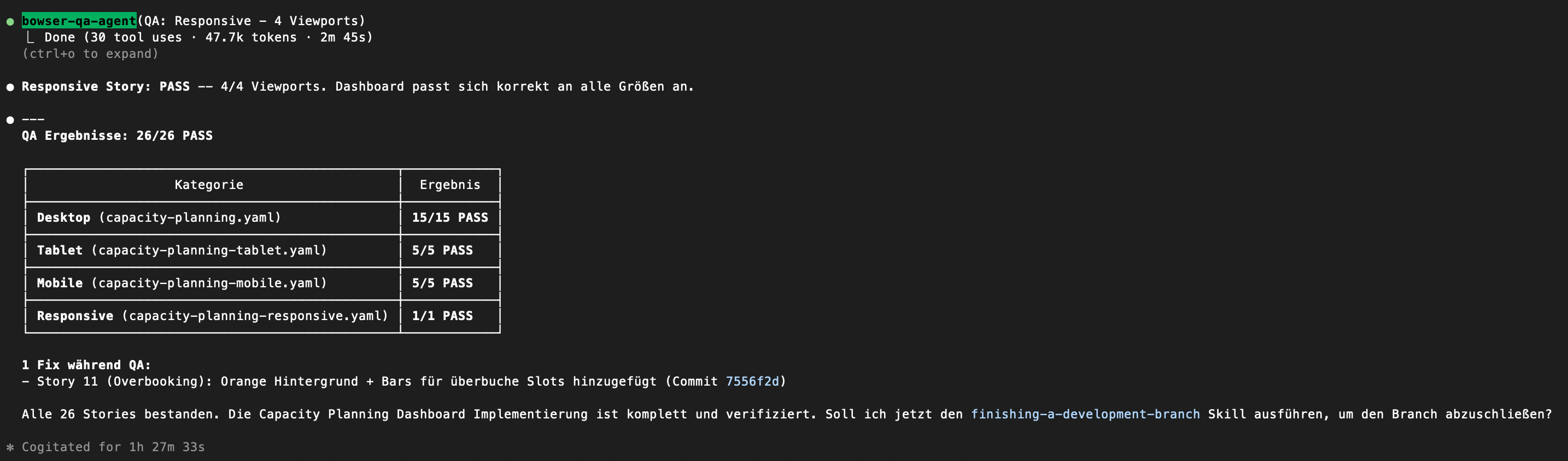
73 User Stories. In 12 Dateien. Vertriebscockpit, Tagessteuerung, Kapazitätsplanung. Responsive-Tests für jede Auflösung. Der Agent versteht die Workflows auf Deutsch und klickt sich durch die App wie ein echter Nutzer.
Tagsüber coden. Nachts testen lassen.
Diese Woche hab ich das gebaut. Und direkt benutzt.
Zum Coden nehme ich Opus. Zum Testen Sonnet. Opus ist gründlicher. Sonnet ist schneller. Zusammen ergibt das einen Loop der sich selbst korrigiert.
Ich mache eine Änderung. Sonnet testet das Frontend. Klickt sich durch die App. Guckt ob Buttons funktionieren, ob Formulare validieren, ob die Navigation stimmt.
Und wenn was kaputt ist, kriege ich halt sofort Feedback. Opus fixt es. Sonnet testet nochmal.
Und das Beste daran: Ich muss nicht mal dabei sein.
Tagsüber implementiere ich. Abends starte ich die Tests. 73 Stories laufen über Nacht durch. Drei Agents parallel, einer pro Dashboard. Jeder Agent nimmt sich eine Story, testet sie, macht Screenshots, nimmt sich die nächste.
Morgens mache ich den Laptop auf. Und da liegen die Ergebnisse. Fertig sortiert. Hier funktioniert was nicht, hier ist ein visueller Fehler, hier hat sich ein Wert verschoben. Keine Checkliste die ich abarbeiten muss. Sondern ein fertiger Report mit Screenshots.
Das ist Testautomatisierung. Aber nicht so wie du sie kennst.
Das ist kein Testing-Trick
Hier ist was mich eigentlich beschäftigt.
Code kann gerade wirklich jeder generieren. Das ist kein Vorteil mehr. Jeder kann sich ein Dashboard zusammenklicken lassen. Die Frage ist halt: Funktioniert es? Auf jedem Gerät? Mit echten Daten? Und hält es, wenn du nächste Woche was änderst?
Das Entscheidende ist nicht, dass ich jetzt schneller teste. Das Entscheidende ist, wie ich mit KI umgehe.
Die meisten geben der KI Aufgaben. Einzelne Aufgaben. “Schreib mir das.” “Teste das.” “Erklär mir das.”
Ich gebe ihr ein System. Skill, Agent, Command. 3 Dateien. Und das System weiß dann selbst was zu tun ist.
Und das ist der eigentliche Unterschied. Nicht welches KI-Modell du benutzt. Nicht welches Tool. Sondern ob du der KI jedes Mal alles von vorne erklärst. Oder ob du einmal ein System baust, das selbst weiß was zu tun ist.
Wer den Agent meistert, meistert Wissensarbeit.
Und das System gehört mir. 3 Markdown-Dateien. Die kann ich in jedes Projekt mitnehmen. Das Vertriebsdashboard mit den 73 Tests heute, das nächste Kundenprojekt morgen. Einmal gebaut, immer nutzbar.
Der CEO sieht sein Dashboard auf dem Handy. Auf dem Laptop. Auf dem Bildschirm im Büro.
Und ich muss nicht mehr hoffen, dass alles funktioniert.
Ich weiß es.
3 Markdown-Dateien. Einmal gebaut, immer nutzbar.
Danke fürs Lesen.
Wenn du Fragen hast oder mir erzählen willst wie du KI in deinen Projekten einsetzt, schreib mir gerne auf LinkedIn.
Bis nächste Woche,
Markus